The Unreasonable Effectiveness of Test Retries: An Android Monorepo Case Study
This post was originally published in the Shopify Engineering blog
At Shopify, we don’t have a QA team, we have a QA culture which means we rely on automated testing to ensure the quality of our mobile apps. A reliable Continuous Integration (CI) system allows our developers to focus on building a high-quality system, knowing with confidence that if something is wrong, our test suite will catch it. To create this confidence, we have extensive test suites that include integration tests, unit tests, screenshot tests, instrumentation tests, and linting. But every large test suite has an enemy: flakiness.
A flaky test can exhibit both a passing and failing result with the same code and requires a resilient system that can recover from those failures. Tests can fail for different reasons that aren’t related to the test itself: network or infrastructure problems, bugs in the software that runs the tests, or even cosmic rays.
Last year, we moved our Android apps and libraries to a monorepo and increased the size of our Android team. This meant more people working in the same codebase and more tests executed when a commit merged to master (we only run the entire test suite on the master branch. For other branches only the tests related to what have changed are run). It’s only logical that the pass rate of our test suites took a hit.
Let’s assume that every test we execute is [independent](https://en.wikipedia.org/wiki/Independence_(probability_theory) of each other (events like network flakiness affect all tests, but we’re not taking that into account here) and passes 99.95% of the time. We execute pipelines that each contain 100 tests. Given the probability of a test, we can estimate that the pipeline will pass 0.9995100 = 95% of the time. However, the entire test suite is made up of 20 pipelines with the same pass probability so it will pass 0.9520 = 35% of the time.
This wasn’t good and we had to improve our CI pass rate.
Developers lose trust in the test infrastructure when CI is red most of the time due to test flakiness or infrastructure issues. They’ll start assuming that every failure is a false positive caused by flakiness. Once this happens, we’ve lost the battle and gaining that developer’s trust back is difficult. So, we decided to tackle this problem in the simplest way: retrying failures.
Retries are a simple, yet powerful mechanism to increase the pass rate of our test suite. When executing tests, we believe in a fail-fast system. The earlier we get feedback, the faster we can move and that’s our end goal. Using retries may sound counterintuitive, but almost always, a slightly slower build is preferable over a user having to manually retry a build because of a flaky failure.
When retrying tests once, the chances of failing CI due to a single test would require that test to fail twice.Using the same assumptions as before, the chances of that happening are 0.05% · 0.05% = 0.000025% for each test. That translates to a 99.999975% pass rate for each test. Performing the same calculation as before, for each pipeline we would expect a pass rate of 0.99999975100 = 99.9975%, and for the entire CI suite, 0.99997520 = 99.95%. Simply by retrying failing tests, the theoretical pass rate of our full CI suite increases from 35% to 99.95%.
In each of our builds, many different systems are involved and things can go wrong while setting up the test environment. Docker can fail to load the container, bundler can fail while installing some dependencies, and so can git fetch. All of those failures can be retried. We have identified some of them as retriable failures, which means they can be retried within the same job, so we don’t need to initialize the entire test environment again.
Some other failures aren’t as easy to retry in the same job because of its side effects. Those are known as fatal failures, and we need to reload the test environment altogether. This is slower than a retriable failure, but it’s definitely faster than waiting for the developer to retry the job manually, or spend time trying to figure why a certain task failed to finally realize that the solution was retrying.
Finally, we have test failures. As we have seen, a test can be flaky. They can fail for multiple reasons, and based on our data, screenshot tests are flakier than the rest. If we detect a failure in a test, that single test is retried up to three times.
 The message displayed when a test fails and it’s retried.
The message displayed when a test fails and it’s retried.
Retries in general and test retries, in particular, aren’t ideal. They work but make CI slower and can hide reliability issues. At the end of the day, we want our developers to have a reliable CI while encouraging them to fix test flakiness if possible. For this reason, we detect all the tests that pass after a retry and notify the developers so the problem doesn’t go unnoticed. We think that a test that passes in a second attempt shouldn’t be treated like a failure, but as a warning that something can be improved. * To reduce the flakiness of builds these are the tips we recommend besides retry mechanisms:
- Don’t depend on unreliable components in your builds. Try to identify the unreliable components of your system and don’t depend on them if possible. Unfortunately, most of the time this is not possible and we need those unreliable components.
- Work on making the component more reliable. Try to understand why the component isn’t reliable enough for your use case. If that component is under your control, make changes to increase reliability.
- Apply caching to invoke the unreliable component less often. We need to interact with external services for different reasons. A common case is to download dependencies. Instead of downloading them for every build, we can build a cache to reduce our interactions with this external service and therefore gaining in resiliency.
These tips are exactly what did from an infrastructure point of view. When this project started, the pass rate in our Android app pipeline was 31%. After identifying and applying retry mechanisms to the sources of flakiness and adding some cache to the gradle builds we managed to increase it to almost 90%.
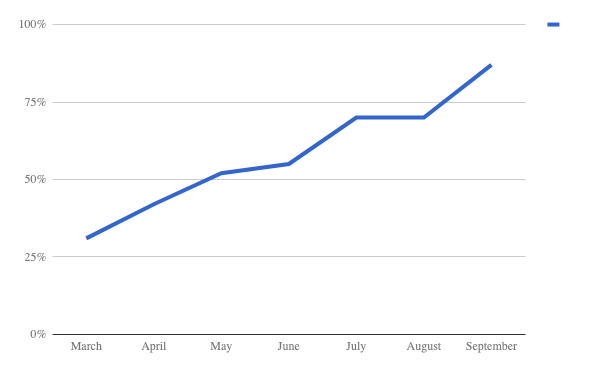
Pass rate plot from March to September Something similar happened in our iOS repository.
After improving our CI infrastructure, adding the previously discussed retry mechanisms and applying the tips to reduce flakiness, the pass rate grew from 67% to 97%. It may sound counterintuitive, but thanks to retries we can move faster having slower builds.